AI Hyper computer is a supercomputing system that is optimized to support artificial intelligence (AI) and machine learning (ML) workloads. It’s an integrated system of performance-optimized hardware, open software, ML frameworks, and flexible consumption models
It’s simply a mix of best hardware, and best software for AI workloads, they only do AI workloads and they do it best
In Google Cloud centers they have A3 VMs powered by NVIDIA h100 Tensor Core GPUs. For more speed, they also custom designed 200GB per second IPUs(Intelligent Processing Units) create a separate data channel for GPUs to communicate with each other that bypasses the CPU host
The AI Hyper Computers have 3 layers:
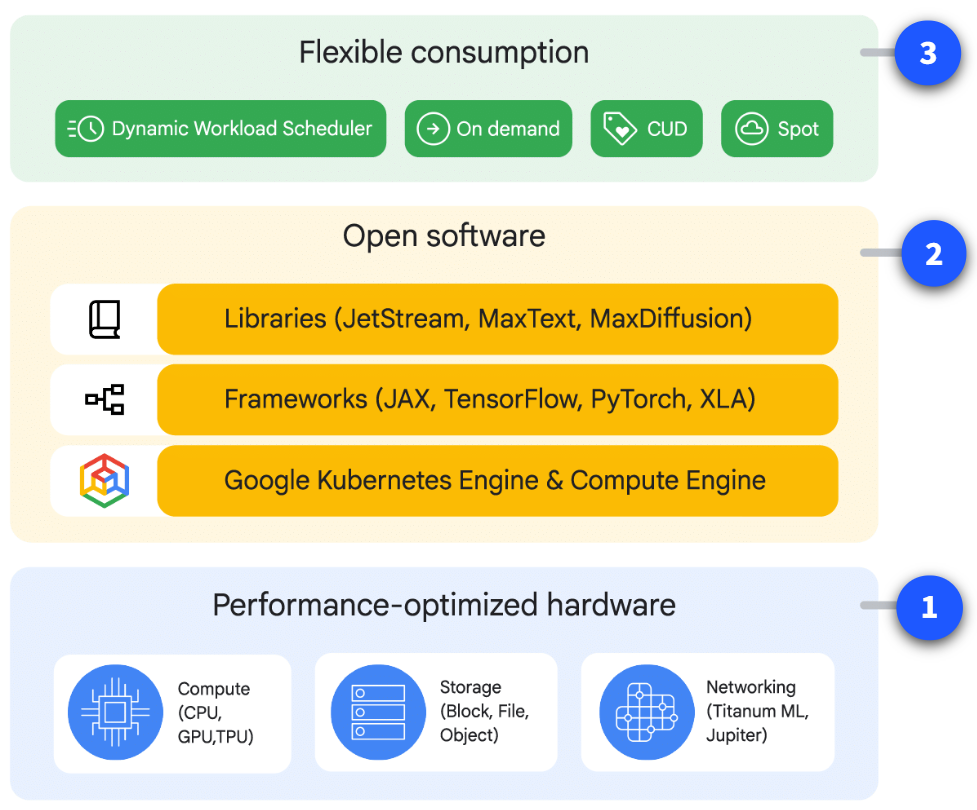
Layer-1: Performance-optimized, purpose-built infrastructure
This foundational layer provides the raw computational power required for demanding AI tasks. It encompasses accelerator resources, high-speed networking, and efficient storage infrastructure, all meticulously optimized for performance at scale
- Compute(CPU, GPU, TPU) - It includes state-of-the-art hardware and CPUs where every it’s needed. These components provide the core processing capabilities for complex model training and inference. They also use highly cost-effective Cloud TPU v5e and G2 VM instances equipped with NVIDIA L4 GPUs
- Storage(Block, File, Object) - It is used for Handling the massive datasets. Hyperdisk ML provides block storage optimized specifically for AI inference/serving, significantly reducing model load times and improving cost efficiency. Additionally, caching capabilities in Cloud Storage FUSE and Parallelstore enhance throughput and reduce latency during both training and inference. A fully managed, high-performance parallel file system like Google Cloud Managed Lustre offers multi-petabyte scalability and significant throughput. Optimized for AI and HPC(high performance computing) applications
- Networking(Titanum ML, Jupiter) - They use Jupiter network fabric and Optical circuit switching (OCS), to create highly scalable data center networks. This infrastructure delivers petabit-scale bandwidth, crucial for large distributed training tasks. For example, A3 Mega VMs leverage this Jupiter fabric. Furthermore, specialized VPC infrastructure optimized for direct GPU-to-GPU connectivity offers up to 3.2 Tbps capacity per VM and supports RDMA for ultra-low latency data transfer, vital for Generative AI and HPC workloads
Layer-2: Open Software
- Orchestration - To deploy and manage a large number of accelerators as a single unit, we can also use Cluster Director for Google Kubernetes Engine, or Cluster Director for Slurm, or directly through Compute Engine APIs. These are Optimized for data access via tools like Google Cloud Storage Fuse with caching and Parallelstore, and efficient job management using the Kueue queuing system
- ML Frameworks - Wide range of ML frameworks are supported with also supporting distributed frameworks like Ray on GKE and cluster blueprints for repeatable deployments
Layer-3: Flexible Consumption
This is the application layer, here we use the platform and it’s pay-as-you-go, but can get discounts via CUDs (Committed use discounts)
This layer is also maintained by Google’s Dynamic Workload Scheduler(DWS) which improves access to in-demand GPUs and TPUs for bursty AI workloads