We deep Dive in Compute part in Performance-Optimized Hardware in AI Hypercomputers
CPUs (Central Processing Unit)
These are general-purpose processors suitable for various tasks, including data preprocessing, control flow in ML programs, and less computationally intensive inference tasks, especially for low-cost inference scenarios. These are not made for training or Matrix Multiplications
At its core, a CPU is a general-purpose processor built on the von Neumann architecture. This means a CPU interacts with software and memory in a sequential manner loading values from memory, performing a calculation and then storing the result back in memory
However, the sequential memory access, often called the von Neumann bottleneck, can limit a CPU’s overall processing speed, as memory access is significantly slower than the calculation itself
GPUs (Parallel Processing)
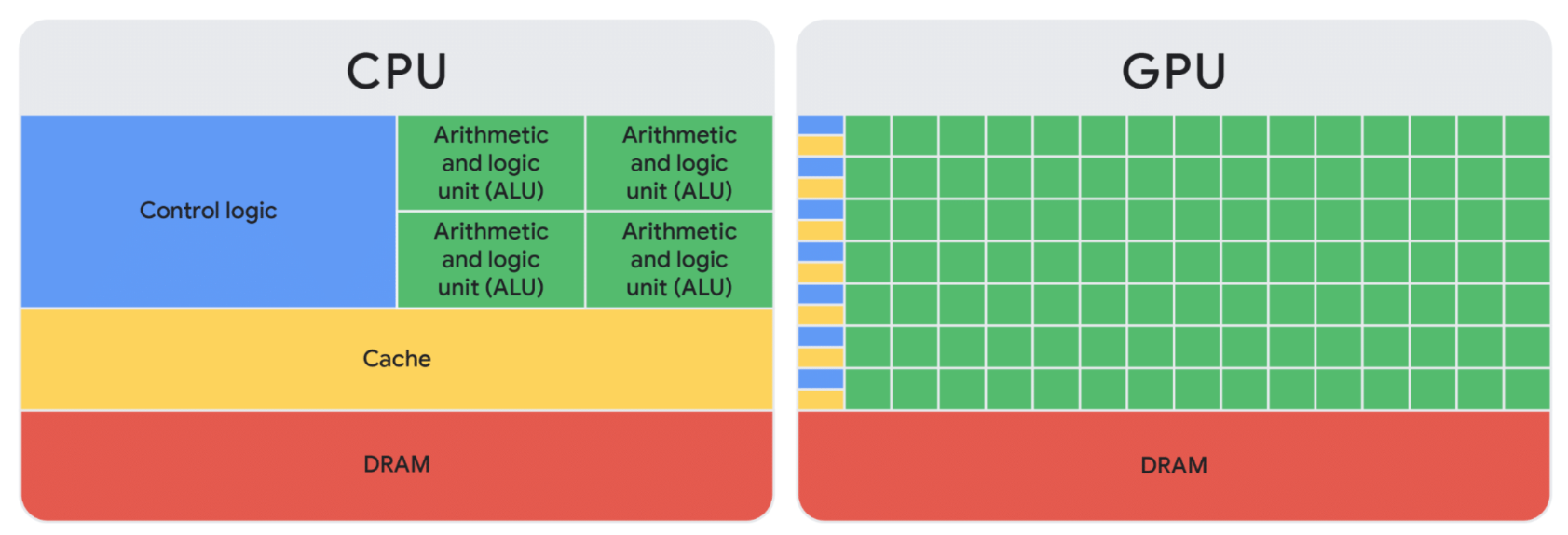
GPUs can do a massive amount of calculations all at the same time. They gain higher throughput by incorporating thousands of arithmetic logic units (ALUs) within a single processor, modern GPUs commonly feature between tens of thousands ALUs. This sheer volume of processors allows for the simultaneous execution of thousands of multiplications and additions
chip layout for comparing the number of ALUs in CPUs and GPUs
| Workload Type | Recommended Machine Type or Series |
|---|---|
| Pre-training Models | A4, A3 Ultra, A3 Mega, A3 High, A2 |
| Fine-tuning Models | A4, A3 Ultra, A3 Mega, A3 High, A2 |
| Serving Inference | A4, A3 Ultra, A3 Mega, A3 High, A2 |
| Graphics-Intensive Workloads | G2, N1+T4 |
| High Performance Computing | Any accelerator-optimized machine series, best fit depends on computation to GPU offload. |
| Here are the Accelerating frameworks which make the GPUs faster |
- CUDA Kernels(Compute Unified Device Architecture): It is NVIDIA’s parallel computing platform and programming model. It’s the lowest-level programming interface for NVIDIA GPUs. When a deep learning framework performs an operation like a matrix multiplication (
torch.matmul) or a convolution, it doesn’t execute a generic CPU instruction. Instead, it dispatches a highly optimized, pre-compiled CUDA kernel to the GPU.- How CUDA powers GPUs:
- CUDA kernels are engineered to leverage the GPU’s Tensor Cores and memory hierarchy (e.g., shared memory, registers)
- They ensure coalesced memory access (accessing memory in a way that aligns with hardware capabilities for maximum bandwidth) and efficient parallel execution.
- This translates directly to superior computational speed compared to CPU execution for parallelizable tasks
- How CUDA powers GPUs:
- XLA Compilers: Accelerated Linear Algebra (XLA) is a domain-specific compiler developed originally by Google. While initially focused on Google’s TPUs, its principles are broadly applicable to other accelerators, including GPUs. Unlike eager execution (where each operation is run immediately), XLA operates on a computation graph. When a series of operations is defined (e.g., a neural network layer), XLA captures this graph. It then performs optimizations on the entire graph before compilation.
- Key XLA optimizations include:
Operator fusion: Combining multiple small operations into a single, larger CUDA kernel, which drastically reduces kernel launch overheads and intermediate memory transfersMemory optimization: Analyzing the graph to minimize memory allocations and deallocationsLayout optimization: Arranging data in memory to better suit the hardware’s access patterns. This process is analogous to a just-in-time (JIT) compiler, but specifically for linear algebra computations, resulting in highly efficient machine code tailored for the target accelerator
- Key XLA optimizations include:
- PyTorch/XLA and JAX/XLA: These are specialized integrations that combine the user-friendly interfaces of their respective frameworks with the powerful optimizations of the XLA compiler
PyTorch/XLA: This integration allows PyTorch models to leverage XLA’s optimizations. You define your model in standard PyTorch, andtorch_xlatransparently converts the computational graph to XLA’s intermediate representation for compilation and execution. It also offers features like gradient checkpointing for memory efficiency and enhanced distributed training capabilities (e.g., with SPMD support), crucial for large-scale modelsJAX/XLA: JAX is designed from the ground up with XLA as its core compilation backend. Its functional programming paradigm and tracing capabilities make it particularly well-suited for building and optimizing computation graphs for XLA- Both integrations enable easy performance. Developers can maintain their preferred Pythonic workflow while automatically benefiting from deep compiler-level optimizations. This abstracts away much of the complexity of low-level hardware tuning, leading to throughput improvements (e.g., tokens/second for large language models) and reduced operational costs
Note:
- ML Productivity Goodput: A metric designed to measure the true efficiency of your AI training. It’s not just about how much data your GPUs are processing, but how much effective training progress you’re making
- Runtime Goodput: The core of runtime goodput is the number of useful training steps completed over a given period
- Cost of interruption (badput):
- Runtime Goodput:
- tch : Time since the last checkpoint when a failure occurs.
- trm : Time to resume training after an interruption.
- tre : Time to reschedule the slice
- tw : Goodput Eval period
- N : Number of interruptions
- To maximize runtime goodput, you need to minimize tch and trm. While the time to reschedule (tre) is also crucial, it’s primarily accounted for under scheduling goodput
- Program Goodput: Program goodput, or model FLOP utilization (MFU), is about how efficiently your training program utilizes the underlying GPU hardware. It’s influenced by your distribution strategy, how well compute and communication overlap, optimized memory access, and efficient pipeline design. The XLA compiler, a core component of AI Hypercomputer, helps maximize Program Goodput through out-of-the-box optimizations and scalable APIs like GSPMD
- Custom Kernels with XLA(JAX/PALLAS): For complex computation blocks, you can often achieve better performance by writing custom kernels. Jax/Pallas provides an “escape hatch” to do this for Cloud TPUs and GPUs, supporting both Jax and PyTorch/XLA. Examples include flash attention or block sparse kernels, which can significantly improve program goodput for larger sequence lengths
- Host Offload: Accelerator memory is a limited resource. Host offload is a technique that leverages host DRAM to offload activations computed during the forward pass, reusing them during the backward pass for gradient computation. This saves re-computation cycles and directly improves program goodput
- INT8 Mixed Precision Training using Accurately Quantized Training(AQT): This technique maps a subset of matrix multiplications in the training step to 8-bit integers (int8) to boost training efficiency and program goodput without compromising model convergence
TPUs (Tensor Processing)
See Cloud TPUs