TPUs are Google’s purpose-built accelerators for deep learning, uniting specialized hardware, hierarchical memory, compiler-driven software, and scalable interconnects into a cohesive system that delivers unmatched efficiency for matrix-intensive neural network workloads
Why TPUs Matter ?
Modern machine learning workloads are dominated by massive matrix multiplications. CPUs handle general tasks but falter on parallel math, while GPUs improve performance with many cores yet retain graphics-oriented hardware. TPUs strip away all nonessential components to focus almost exclusively on tensor operations, achieving orders-of-magnitude gains in speed, energy efficiency, and cost-effectiveness
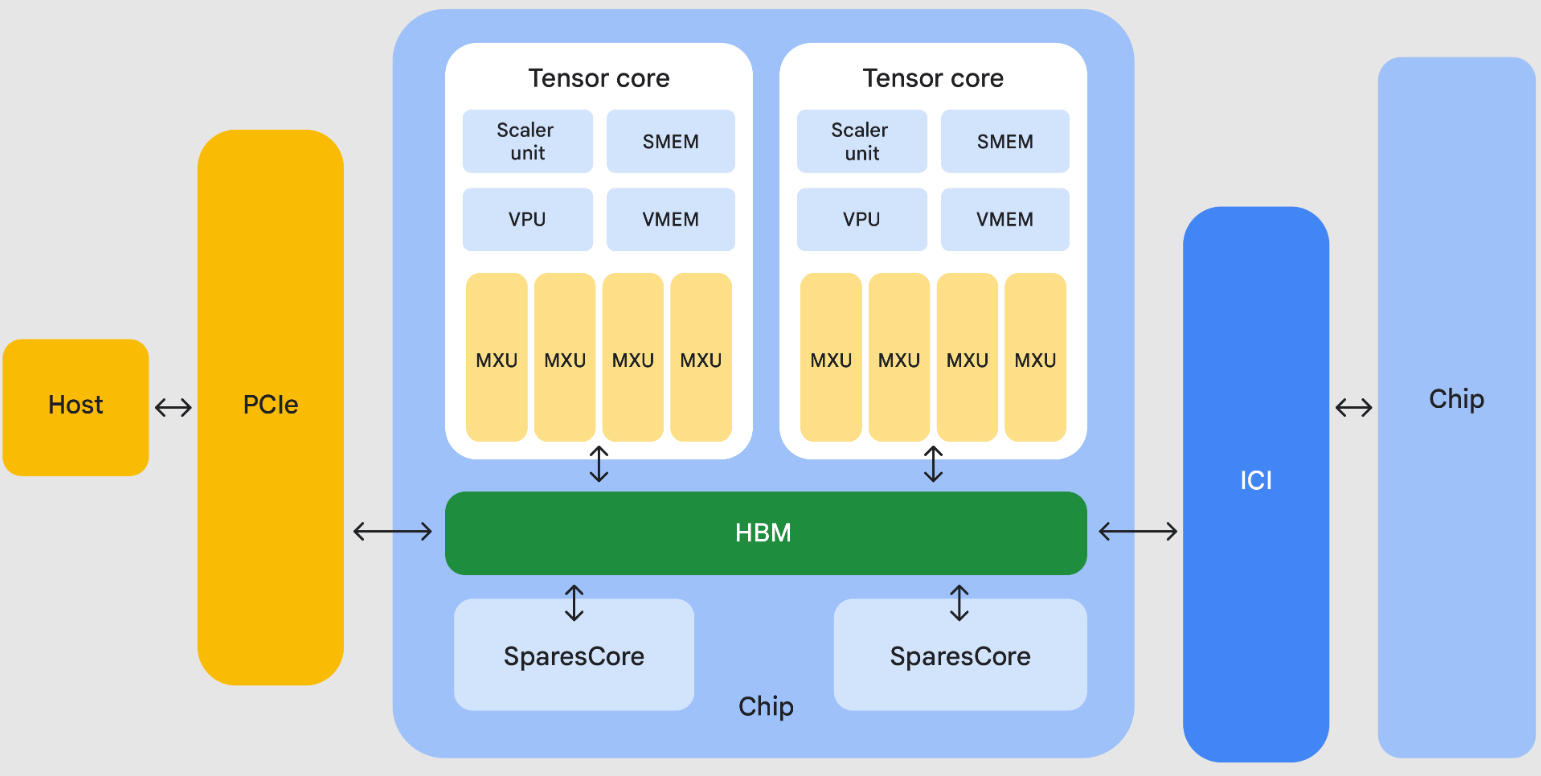
Core Hardware: Systolic Array (MXU)
At the center of each TPU chip lies the Matrix Multiply Unit (MXU), a 2D systolic array of multiply-accumulate units:
- TPU v1–v5: 128×128 array (16,384 MAC units); TPU v6e: 256×256 (65,536 MAC units)
- Data (weights and activations) pulses rhythmically across rows and columns, reusing values locally and minimizing external memory accesses
- Each MXU can perform up to 92 tera-ops/sec, prioritizing throughput over latency
By reusing data in motion, systolic arrays eliminate memory bottlenecks that slow CPUs and GPUs, delivering a dedicated engine for the heart of neural network computation.
Memory Hierarchy
TPUs employ a two-tiered memory system designed for high bandwidth and low latency:
- High Bandwidth Memory (HBM): Vertically stacked modules offering 1.5–3 TB/s throughput, storing model parameters and activations
- On-Chip SRAM (Unified Buffer): 24–28 MB of ultra-fast SRAM on the chip, caching data for immediate use by the MXU and reducing trips to HBM
This hierarchy ensures data flows efficiently from the large-capacity vault (HBM) to the staging area (SRAM) to the compute core, maximizing utilization and minimizing stalls
Complementary Units: Vector & Scalar
While MXUs excel at matrix math, TPUs integrate two additional units to handle the rest:
- Vector Processing Unit (VPU): Executes element-wise operations (additions, activation functions, layer normalization) on 1D arrays
- Scalar Unit: Manages control flow, memory address calculations, and orchestration of data transfers across the chip
These units work in concert so that small but essential tasks never bottleneck the primary systolic engines
Software Integration: XLA Compiler
The XLA (Accelerated Linear Algebra) compiler bridges high-level ML frameworks (TensorFlow, JAX, PyTorch/XLA) and the TPU hardware
- Static Scheduling: Plans data movement, memory tiling, and instruction order ahead of time, enabling a streamlined hardware design free of dynamic scheduling overhead
- Operation Tiling & Padding: Breaks computations into optimal 128×128 (or 256×256) tiles, automatically pads tensors, and aligns shapes for maximum MXU utilization
- Memory Optimization: Allocates data across HBM and SRAM to minimize bandwidth waste and latency spikes
By shifting complexity from hardware to software, XLA allows TPUs to maintain simplicity and focus on raw compute performance
Scaling: Chips → Cubes → Pods → Slices
TPUs scale from a single chip to global clusters with custom interconnects:
- Chip: Contains one or more Tensor Cores (MXU + VPU + Scalar Unit)
- Cube (Rack): 64 chips in a 4×4×4 grid with direct copper connections for ultra-fast local communication
- Pod: Thousands of chips connected by optical links, forming a supercomputer for training massive models
- Slice: Flexible subsets of a pod (from 4 chips up to full pods), optimized for specific workloads
- Inter-Chip Interconnect (ICI): ~450 GB/s links in a 3D torus topology, minimizing latency and maximizing bandwidth across chips
This hierarchy, from building blocks to global clusters, ensures TPU systems can handle everything from small inference tasks to training state-of-the-art models like Gemini or Alpha Fold
Performance & Efficiency
Throughput Focus: Designed for large-batch, high-utilization workloads rather than low-latency single queriesEnergy Efficiency: 83× better than CPUs and 29× better than GPUs in performance-per-wattCost Efficiency: Competitive cloud pricing (e.g., TPU v6e at $2.70/hour), with scale-out reducing per-unit cost for large models
TPUs deliver higher FLOPS per watt by eliminating unnecessary hardware and optimizing every layer of the stack
Note: TPU vs. GPU
- Choose TPUs for large-scale TensorFlow/JAX workloads on Google Cloud needing maximum throughput and efficiency
- Choose GPUs for multi-framework flexibility (PyTorch, CUDA), broader cloud options, and workloads requiring high VRAM per device