Q The major areas where the prover spends its time ?
A
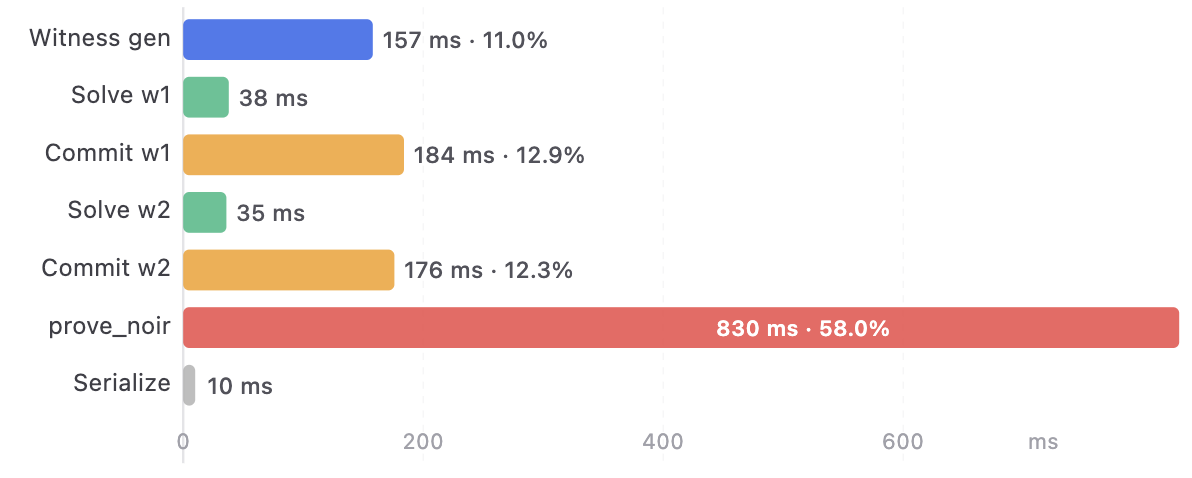 The total
The total prove command takes 2,140 ms wall-clock, with 570 ms spent on XZ-decompressing the prover key and 10 ms writing the proof
Q The most fundamental operations in the overall proving flow ?
A
- Dominant (>10% CPU each)
- BN254 Montgomery Multiplication (28.1%): The single hottest function. A 4-limb Montgomery multiply on a 254-bit prime field element (~15–20 ns per call on Apple Silicon). Used by the NTT, sumcheck, weight folding, and geometric accumulation, but NOT by Skyscraper (see below)
- Skyscraper Hash Compression (19.0%): Merkle tree hash for polynomial commitments. Processes 64-byte blocks through a byte-level S-box (bitwise rotate + AND + XOR) followed by Montgomery squaring via
bn254_multiplier::montgomery_square_log_interleaved_4, a separate ARM NEON SIMD implementation in theskyscraper/bn254-multipliercrate, completely independent ofark_ff::mul_assign - NTT / Reed-Solomon Encoding (20.5% total): Cooley-Tukey FFT over BN254 Fr. The compute portion (butterfly operations) is 15.2%, and the data transpose (shuffling 32 MB between row-major and column-major) adds 5.3%. The largest NTT operates on 1M-element polynomials
- Significant (3–10% each)
- Weight folding / mixed_dot (6.1%) - dense multiply-accumulate over 1M-element vectors
- Sumcheck prover (5.5%) - cubic polynomial evaluation at 3 points per variable, parallelized via Rayon
- XZ/LZMA decompression (5.5%) - prover key I/O, not proving work
- Notable (<3%)
- Sparse matrix ops (2.4%), evaluate_gamma_block (1.4%), geometric_accumulate (1.3%)
- Witness generation is only 0.6% - the Noir ACVM is cheap
Note: WHIR Round Cost Decay — Each WHIR proof runs 5 FRI-like rounds with geometrically shrinking domains. Round 1 (domain 1M) costs 75.6 ms for IRS Commit alone; by round 5 (input domain 32) it’s 6.4 ms. The IRS Commit phase (NTT + Merkle) dominates every round.
Q By how much would proving time decrease if field multiplication took half as long as it does now? Would the improvement be minor or significant, and why?
A First, we analyze who calls ark_ff::mul_assign:
 Programmatic analysis of all 7,600 flamegraph samples traced every
Programmatic analysis of all 7,600 flamegraph samples traced every mul_assign leaf sample to its direct caller:
| Caller | Samples | % of mul |
|---|---|---|
| NTT butterflies | 1,546 | 72.3% |
| mixed_dot | 252 | 11.8% |
| geometric_accumulate | 184 | 8.6% |
| Sumcheck | 92 | 4.3% |
| evaluate_gamma_block | 25 | 1.2% |
| Other | 39 | 1.8% |
| Skyscraper | 0 | 0.0% |
Skyscraper contributes zero ark_ff::mul_assign calls. It uses a completely separate SIMD Montgomery implementation (bn254_multiplier). The 19% of CPU time in Skyscraper is unaffected by any ark_ff speedup |
A 2× ark_ff::mul_assign speedup saves ~240 ms off a 1,400 ms prove, a 1.21× proving speedup (17% reduction). That’s noticeable. But it’s not transformative because:
- Skyscraper (19% of CPU) is completely unaffected - separate SIMD Montgomery implementation
- NTT transposes (5.3%) are memory-bound, halving mul doesn’t help memory shuffling
- OS overhead (4.9%) and I/O (5.5%) are fixed costs
- Amdahl’s Law → even at ∞ speed, mul_assign can only remove 34.3% of proving time, capping the theoretical max at a 1.52× proving speedup.
Additional Data
Memory Profile
Peak memory reaches 908 MB during prove_noir when R1CS matrices, the full witness, transposed matrices, and eq(alpha) evaluations coexist. System-level RSS peaks at 1.36 GB
Consistency (3 runs, /usr/bin/time -l)
| Metric | Run 1 | Run 2 | Run 3 | Variance |
|---|---|---|---|---|
| Instructions | 188.589 B | 188.607 B | 188.627 B | <0.02% |
| Cycles | 47.157 B | 47.271 B | 47.368 B | <0.4% |
| Peak RSS | 1.363 GB | 1.357 GB | 1.362 GB | <0.4% |
| IPC: 188.6B / 47.3B ≈ 3.99 | ||||
| near Apple Silicon’s theoretical max, confirming a compute-bound workload |