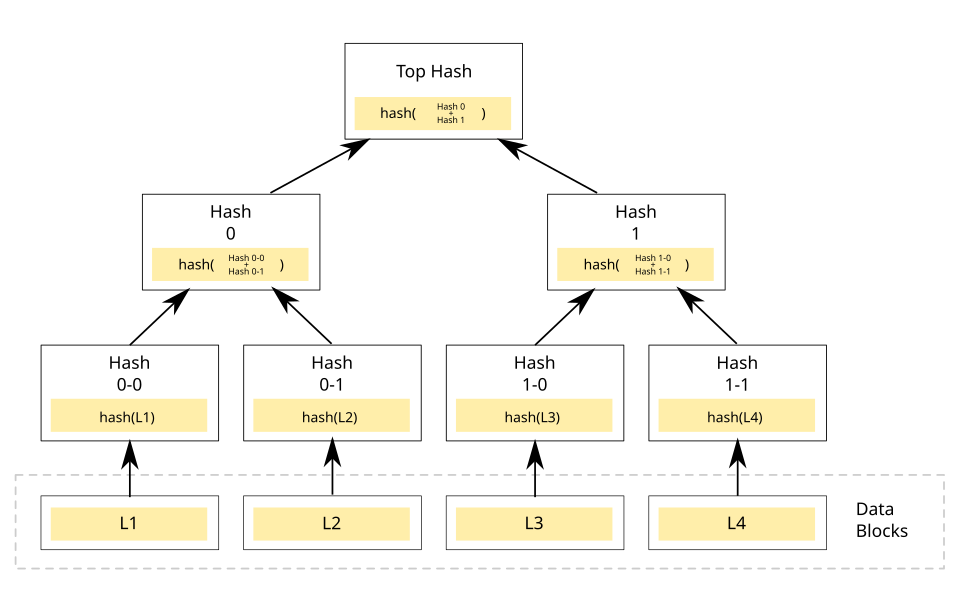
A hierarchical data structure used to efficiently verify the integrity and inclusion of data in a large set
Git
Let’s say we’re working on a project which is tracked by git, and the project has one folder src and two files main.go and main.rs. Let’s figure out how it tracks data and how Git uses Merkle trees w.r.t. multiple possible changes we make to the project
Here is the data stored in the folder structure:
- Root folder – stores the hash of
src(and metadata like mode/type) - src folder (tree object) – stores entries containing: filename (
main.go,main.rs), file mode, and pointer (hash) to the corresponding file content (blob)
here are some scenarios
- One file in
srcis renamed- The file content hash stays the same (blob is unchanged)
- The tree object
srcchanges, because filenames are part of the tree data - This creates a new tree object for
src - The change propagates upward, so the root tree hash also changes
- IDE shows this as a rename (often green diff), but internally Git sees:
- old tree → new tree
- same blob hash, different filename entry
- File content changes in
main.go- The blob hash changes, because file content changes
- A new blob object is created
- The
srctree now points to the new blob hash - The old blob remains in the object database (Git is immutable)
- This change again propagates upward to the root tree and commit
- Locally: Git stores full blobs, not diffs. Old and new versions both exist as separate blobs
- During network transfer (push/pull): Git may send packfiles(.pat) that use delta compression internally to reduce size
Q Why is Git not considered a “block chain”? as each data block is hashed. Modifying (bit error or attack) an intermediate block will be noticed when the saved hash and the actual hash deviate
A Git’s directed acyclic graph is exactly that, a merkle tree where each node (tag, commit, tree, or blob object) is labeled with the hash of its content and the label of its “child”. Note that for commits, the “child” term conflicts a bit with Git’s understanding of parents: Parent commits are the children of commits, we just need to look at the graph as a tree that keeps growing by re-rooting it
And yes Blockchain is a distributed “Git”, with one change, Blockchain is immutable (Git allows rebase), and also relies on consensus via redundant network mining and security is increased by the size of the network
Dynamo DB
When handling DBs at scale, we have different nodes in a cluster, and we use Consistent Hashing when a new node is added, we need to migrate/copy part of the data from existing nodes to the new node
The problem here is that we want to have an exact copy of all key–value pairs in a hash range (say 0–9) from the old node into the newly added node. But the data is constantly being updated on the old node(as it’s real time distributed system), which can lead to an inconsistent state in the copied data
Thus, we need to figure out a way to:
- detect inconsistencies efficiently
- minimize data transfer between nodes
Here we use merkle trees
Merkle trees are not used to speed up the copy itself, but to efficiently compare replicas and detect which parts of the data differ
However, in a real-time distributed system:
- data changes frequently
- a Merkle tree built at time “t” may already be stale by the time it is compared on another node
So the system must tolerate continuous divergence and still converge eventually. so here are the approaches
- Have a down time and compare and bring two systems backup and until this process happen keep the changes in queue or another db - not ideal
- Merkle-tree-based anti-entropy
- Each node maintains a Merkle tree per key range (per virtual node)
- Trees are exchanged between replicas
- If the root hashes match, data is consistent
- If not, the system:
- recursively compares subtrees
- identifies only the divergent key ranges
- transfers only the differing data
Blockchain
Let’s say I’ve done a transaction and it’s included on the blockchain in some block
Now the question is: “how can I be sure that this transaction is actually mine, that it went through, and that it hasn’t been tampered with?“
here are the approaches
- Download the whole blockchain from genesis and compute each block hash, header, transaction and signature from one block to another and land at your transaction of your block and confirm - works, but too long and waste of compute
- Merkle proofs (SPV – Simplified Payment Verification)
- There are two separate cryptographic guarantees:
- Digital signatures → prove authorization (you signed the transaction)
- Merkle proofs → prove inclusion (your transaction is in the block)
- How Merkle trees are used
- Each transaction will have a hash, let’s say a block have 4 transactions, so each block will generate a merkle tree of height 2(excluding leaves) and each block root is a node to another blocks root, and this grows and land at a root node, and here if anything changes the whole hashes break, so if the hashes break the transaction is not true and in most cases it doesn’t the transaction is true and it’s done
- To prove your transaction is in the block, we only need:
- transaction hash
- a Merkle proof (sibling hashes along the path to the root)
- There are two separate cryptographic guarantees:
graph TD Chain-level Merkle Tree (Inverted) ===================== ===================== subgraph Block_1["Block 1"] direction TB B1Root["Merkle Root B1"] B1Root --> B1H12["H12"] B1Root --> B1H34["H34"] B1H12 --> B1T1["Tx1"] B1H12 --> B1T2["Tx2"] B1H34 --> B1T3["Tx3"] B1H34 --> B1T4["Tx4"] end Block 2 ===================== ===================== subgraph Block_3["Block 3"] direction TB B3Root["Merkle Root B3"] B3Root --> B3H12["H12"] B3Root --> B3H34["H34"] B3H12 --> B3T1["Tx1"] B3H12 --> B3T2["Tx2"] B3H34 --> B3T3["Tx3"] B3H34 --> B3T4["Tx4"] end Block 4 %% ===================== subgraph Block_4["Block 4"] direction TB B4Root["Merkle Root B4"] B4Root --> B4H12["H12"] B4Root --> B4H34["H34"] B4H12 --> B4T1["Tx1"] B4H12 --> B4T2["Tx2"] B4H34 --> B4T3["Tx3"] B4H34 --> B4T4["Tx4"] end
Using this proof, you can recompute the Merkle root and check: “does it match the Merkle root in the block header?“. If yes, our transaction is provably included in that block
Q What SPV clients actually verify ?
A An SPV (light) client verifies:
- Block headers only (very small data)
- Proof-of-work / consensus rules
- Merkle proof of inclusion for the transaction
But one thing to remember is Merkle inclusion ≠ transaction validity as a malicious miner could include an invalid transaction. Here SPV assumes the majority of hash power / stake is honest Finality increases with more confirmations and deeper blocks
That’s why wallets say: “Wait for 6 confirmations”
Incremental Merkle Trees
When we talk about smart contracts, in most cases standard Merkle trees are stored off-chain, and only the Merkle root is stored on-chain and when a user wants to verify data presence, they provide “leaf data” and “a Merkle proof” (sibling hashes along the path)
The smart contract:
- hashes the leaf
- reconstructs the path to the root using the proof
- recomputes the Merkle root
- compares it with the root stored on-chain
If the roots match, the data is proven to be included
However, in some cases we need the Merkle tree to be maintained on-chain, not just the root A real example is Tornado Cash, where:
- commitments are added over time
- the tree must be updated incrementally
- recomputing the whole tree on every insert would exceed block gas limits
If we had to recompute the entire tree for each insertion, transactions would fail due to gas / block limits
So the question is: “we have data stored in a smart contract as a Merkle tree, and now we want to update it. How can we do this without a centralized entity and without recomputing the whole tree?”
We use Incremental Merkle Trees (IMT), these are efficient, scalable and updatable on-chain merkle trees. This allow us to append new leaves and update the Merkle root by using O(depth) hash operations instead of rebuilding the entire tree
- Fixed depth / size
- Depth = number of hash operations from any leaf to the root. Tree capacity =
2^depthleaves - To insert one leaf, we need at most depth hash operations
- here we compute one hash per level, not all nodes at that level.
- Depth = number of hash operations from any leaf to the root. Tree capacity =
- Leaves initialized with “zero” values
- All leaves are initially populated with a default constant value
- Not literal zero, it’s just a fixed hash
- for example, Tornado Cash uses a constant like
hash("tornado")
Here we precompute and cache “zero leaf” and “zero subtree roots for every depth” and these act as placeholders for unoccupied parts of the tree. Here are the operations
- Insertions(Incremental Insertions)
- Leaves are filled from left to right
- When a value is inserted, it replaces a default “zero” leaf(constant value)
- Once a subtree is fully populated, it never needs to be recomputed again
- Instead of caching every intermediate node, we cache “The smallest set of non-overlapping subtrees that fully represent the current state of the tree”
- Binary Index Insight (Key Optimization)
- The set of cached subtrees always corresponds to the binary representation of the current leaf index
- For example, if we “Insert at index 13”, in binary which is
1101, this means (depth is 0-indexed)- one subtree of depth 3
- one subtree of depth 2
- no subtree of depth 1
- one subtree of depth 0
- so, only these subtree roots are stored and these are sufficient to reconstruct the full Merkle root, this makes IMTs gas-efficient
- Left / Right Hashing Rules
- When adding a node, if the leaf index is:
- Even
- the new leaf goes on the left
- it is hashed with the right sibling, which is an unoccupied “zero” leaf
- this produces a subtree of depth 0
- Odd
- the new leaf goes on the right
- it is hashed with the left sibling, which is already occupied
- this subtree root is cached
- Intermediate
- At each level the current subtree root is hashed with:
- either a zero subtree (if the sibling is unoccupied)
- or an occupied cached subtree
- If the resulting subtree contains “no zero” values and it is fully populated then it’s root is stored (cached) in the smart contract
- At each level the current subtree root is hashed with:
- Even
- The same rule applies recursively at each level
- When adding a node, if the leaf index is:
Here Gas cost scales with tree depth, not tree size