The evolution of search infrastructure has become critical as applications scale to handle billions of documents and millions of queries per second. Modern distributed search systems must balance the demanding requirements of high availability, scalability, and low latencies while efficiently managing both indexing and search workloads across multiple nodes
Core Search Infrastructure Components
Inverted Index and Lucene Architecture
Apache Lucene serves as the foundation for most modern search engines, providing fast text-to-inverted-index conversion capabilities. The indexing process involves several critical steps that transform raw text into searchable structures:
- Tokenization: Breaking text into individual terms or tokens by splitting on whitespace and punctuation
- Normalization: Standardizing terms through lowercase conversion, punctuation removal, and character normalization
- Stop Word Removal: Eliminating common words like “the”, “and”, “is” that carry minimal semantic weight
- Stemming & Lemmatization: Converting words to their root forms (e.g., “running” → “run”) and bringing past/present tense variations to consistent forms
The inverted index structure consists of two fundamental components:
- Term Dictionary: A sorted list of all unique terms found across documents, enabling fast binary search lookups
- Postings Lists: For each term, a list indicating which documents contain that term, along with frequency and position information
Retrieval Methods and Ranking Algorithms
- Boolean Retrieval Model handles exact match queries using AND, OR, and NOT operations but struggles with relevance ranking and relationship-based queries.
- Probabilistic Models and BM25 represent the current gold standard for lexical search. BM25 (Best Match 25) incorporates several sophisticated components:
- Term Frequency Saturation: Prevents over-emphasis of repeated terms through a saturation function
- Inverse Document Frequency: Assigns higher weights to rare, discriminative terms
- Document Length Normalization: Ensures fair scoring across documents of varying lengths
Note:
- The BM25 scoring formula balances these factors with tunable parameters k₁ (controlling saturation effects, typically 1.2-2.0) and b (controlling document length influence, typically 0.75)
- Vector Space Models and Neural Information Retrieval leverage semantic embeddings to understand query intent beyond exact keyword matching. These approaches excel at handling synonyms, multilingual content, and contextual similarity
Vector Search and Semantic Understanding
Semantic Search Implementation
Semantic search transcends lexical matching by understanding meaning and context through vector embeddings. Unlike traditional keyword search that only finds exact matches, semantic search can connect related concepts. for example, finding “soccer” content when searching for “football”. Vector Indexing Strategies are crucial for managing high-dimensional embedding data:
- Locality Sensitive Hashing (LSH) groups similar vectors into buckets using hash functions that maximize collision probability for similar items. While computationally efficient for low-dimensional data, LSH becomes impractical as dimensionality increases due to the curse of dimensionality
- Hierarchical Navigable Small Worlds (HNSW) creates multi-layered graphs where each layer contains increasingly detailed subsets of the data. The algorithm navigates from coarse upper layers to fine lower layers, effectively “jumping over” irrelevant data points
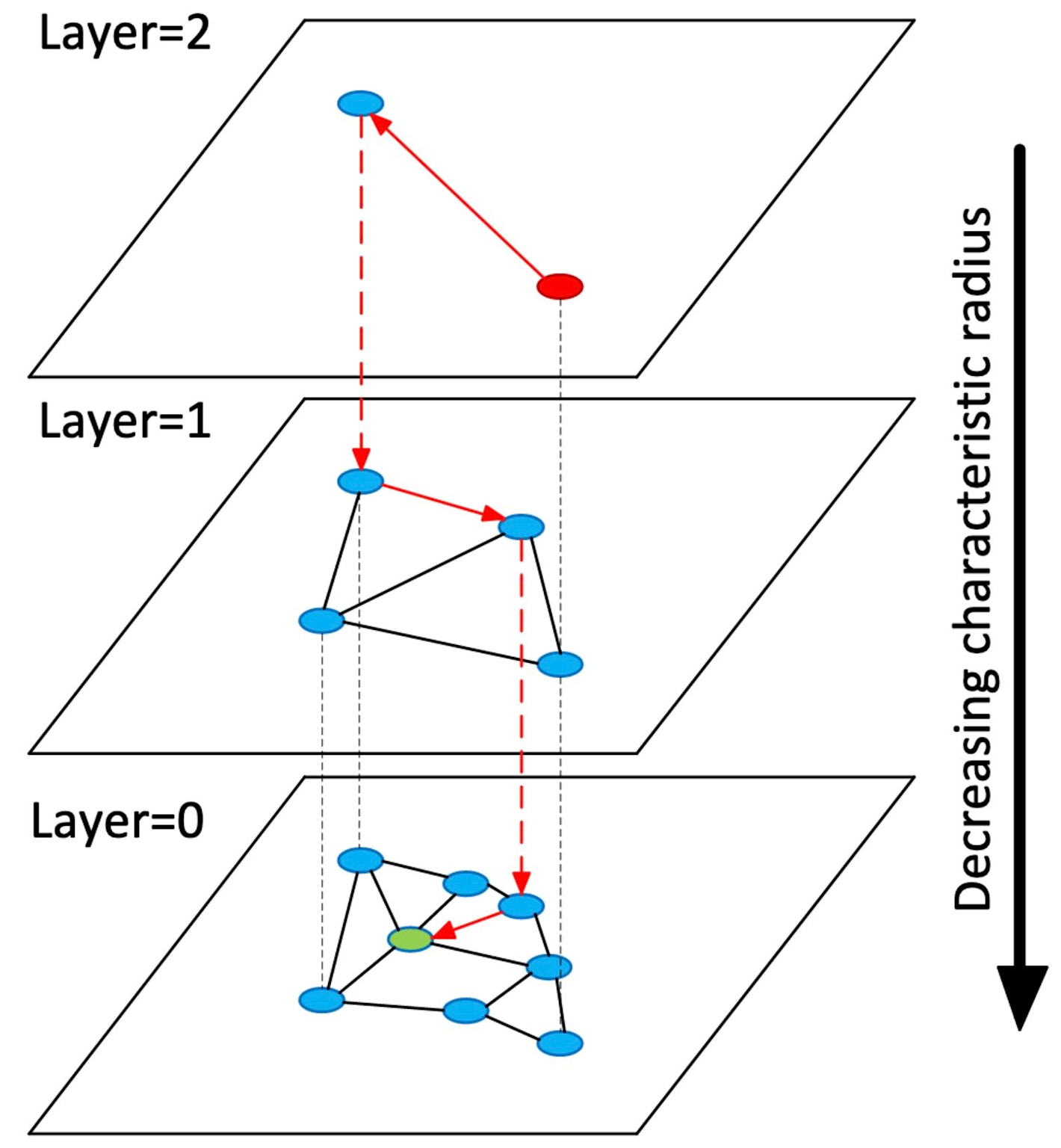 Visualization of a hierarchical navigable small worlds (HNSW) graph showing three layers with decreasing characteristic radius from top to bottom and inter-layer connections
Visualization of a hierarchical navigable small worlds (HNSW) graph showing three layers with decreasing characteristic radius from top to bottom and inter-layer connections
This approach provides excellent performance characteristics: - Superior memory efficiency by caching only the top layers
- Dynamic insert/delete capabilities without index rebuilding
- Scalable approximate nearest neighbor search suitable for production systems
Distance Metrics and Similarity Calculations
Vector similarity calculation relies on mathematical distance metrics, each serving different use cases:
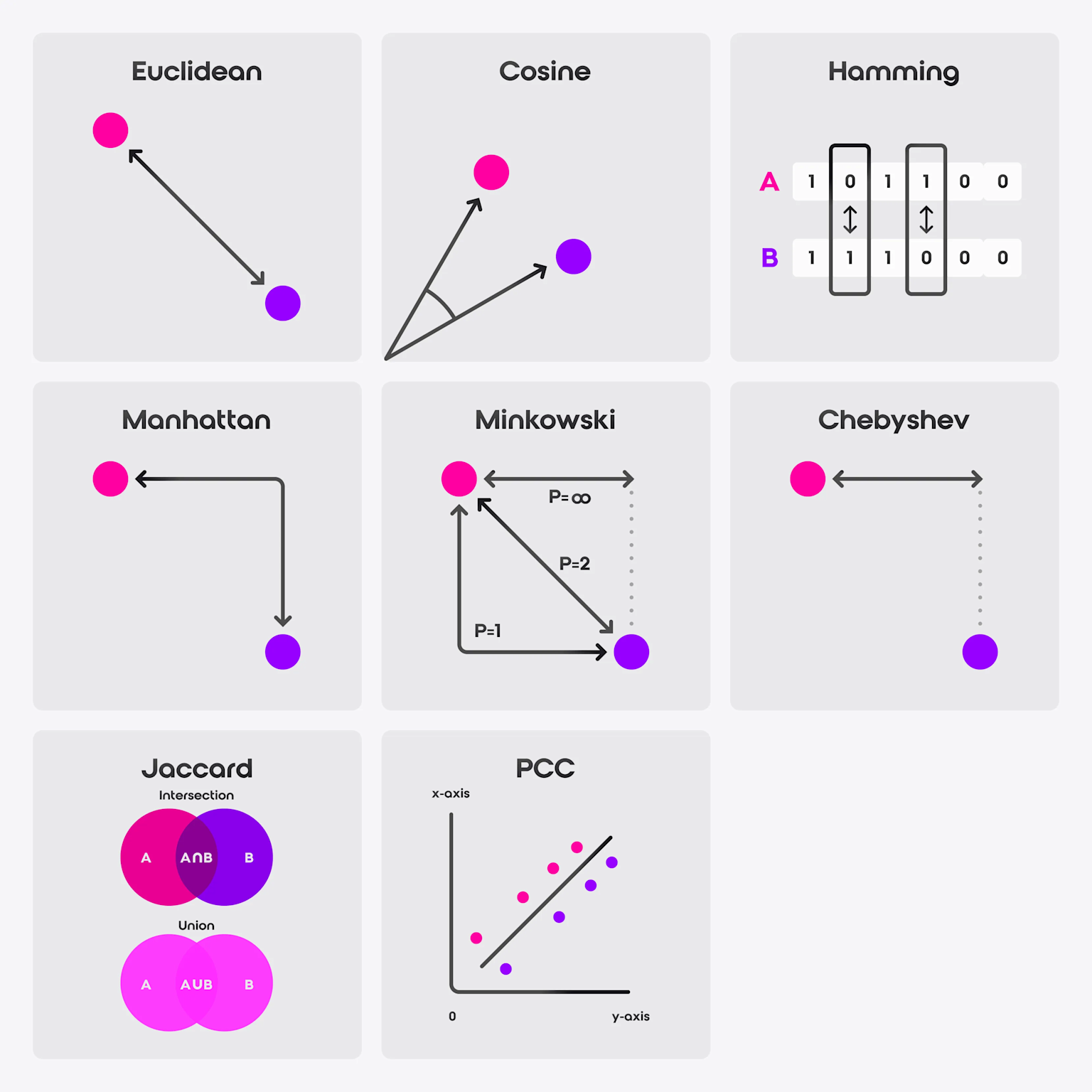 Visualization of various vector distance and similarity metrics including Euclidean, Cosine, Manhattan, Minkowski, Chebyshev, Hamming, Jaccard, and Pearson Correlation Coefficient.
Visualization of various vector distance and similarity metrics including Euclidean, Cosine, Manhattan, Minkowski, Chebyshev, Hamming, Jaccard, and Pearson Correlation Coefficient.
- Cosine Similarity measures the angle between vectors, making it ideal for NLP applications where document length varies significantly. Two documents may have different magnitudes but similar semantic content, making cosine similarity more appropriate than Euclidean distance
- Euclidean Distance calculates straight-line distance between vectors, suitable for scenarios where magnitude matters. This metric works well for image embeddings and cases where vector magnitude carries semantic meaning
- Manhattan Distance sums absolute coordinate differences, offering faster computation than Euclidean distance while maintaining reasonable accuracy. It’s particularly effective in high-dimensional spaces where computational efficiency matters
- Dot Product combines vector magnitudes with angular similarity, providing rich similarity information when vectors aren’t normalized. For normalized vectors, dot product and cosine similarity produce identical results
Multilingual Search Capabilities
Multilingual semantic search addresses the challenge of cross-language information retrieval using several strategies:
- Multilingual Embeddings train models like multilingual BERT or E5 on diverse language datasets, mapping text from different languages into a shared semantic space. This enables direct cross-language similarity comparison without translation
- Translation-Based Methods convert queries or documents to a common language before indexing, simplifying the search pipeline but introducing potential translation errors. Hybrid approaches combine translation with multilingual embeddings for improved coverage
- E5 Model Implementation requires specific text prefixing: queries must be prefixed with “query: ” and documents with “passage: ” to maintain model accuracy. This attention to model-specific requirements is crucial for optimal performance
Distributed Architecture and Scaling Strategies
Sharding and Data Distribution
Distributed search clusters require sophisticated data partitioning strategies to balance load and maintain performance:
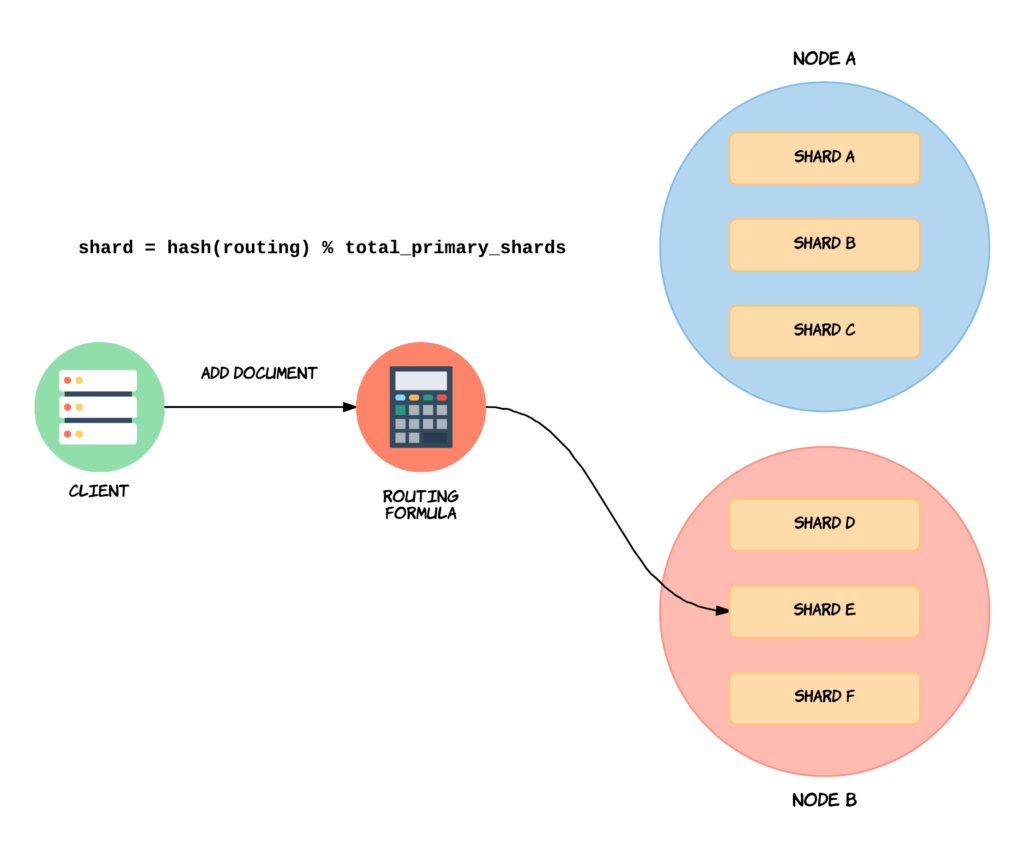 Diagram showing how an Elasticsearch client query is routed to different shards across two clusters for distributed search
Diagram showing how an Elasticsearch client query is routed to different shards across two clusters for distributed search
- Hash-Based Sharding applies hash functions to shard keys, ensuring even data distribution and avoiding hotspots. This approach works well for unpredictable access patterns and uniform workload distribution
- Range-Based Sharding partitions data based on value ranges, keeping related data co-located within shards. This strategy benefits applications with sequential access patterns or range queries
- Geographic Sharding distributes data based on regional boundaries, enabling localized search and reduced latency for location-based queries
- Hybrid Sharding combines multiple strategies based on specific use cases, optimizing for both performance and operational requirements
Elasticsearch Cluster Architecture
The distributed nature of Elasticsearch demonstrates sophisticated cluster management and data organization:
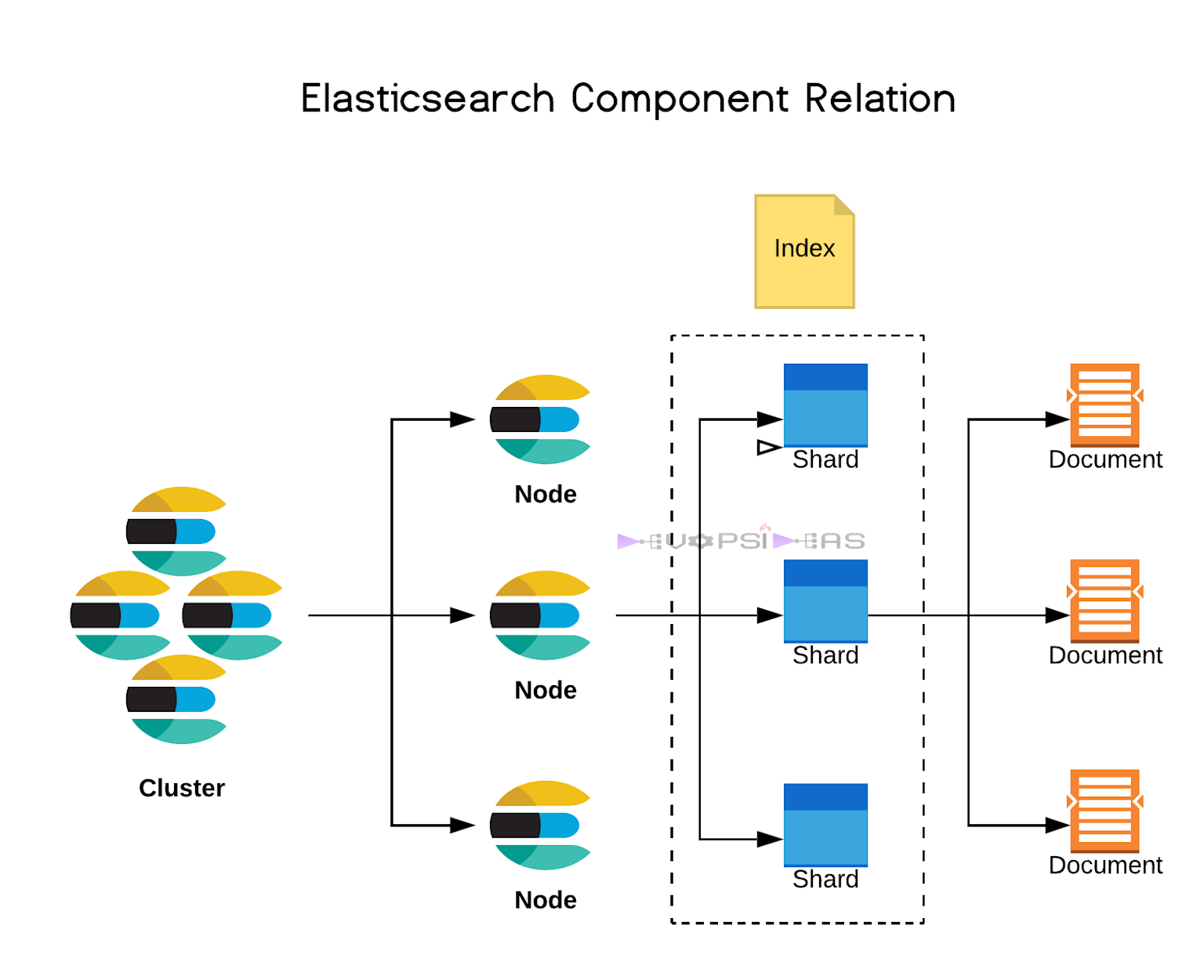 Diagram showing the relationship between Elasticsearch clusters, nodes, shards, indexes, and documents in distributed search architecture
Diagram showing the relationship between Elasticsearch clusters, nodes, shards, indexes, and documents in distributed search architecture
- Cluster Components include multiple nodes, each containing primary shards and replicas. This architecture ensures fault tolerance through replica distribution across different nodes, preventing data loss during node failures
- Shard Distribution Strategy balances primary shards and their replicas across available nodes. For example, if Node 1 contains shard_0, its replica might be placed on Node 2 or Node 3, ensuring data availability even during individual node outages
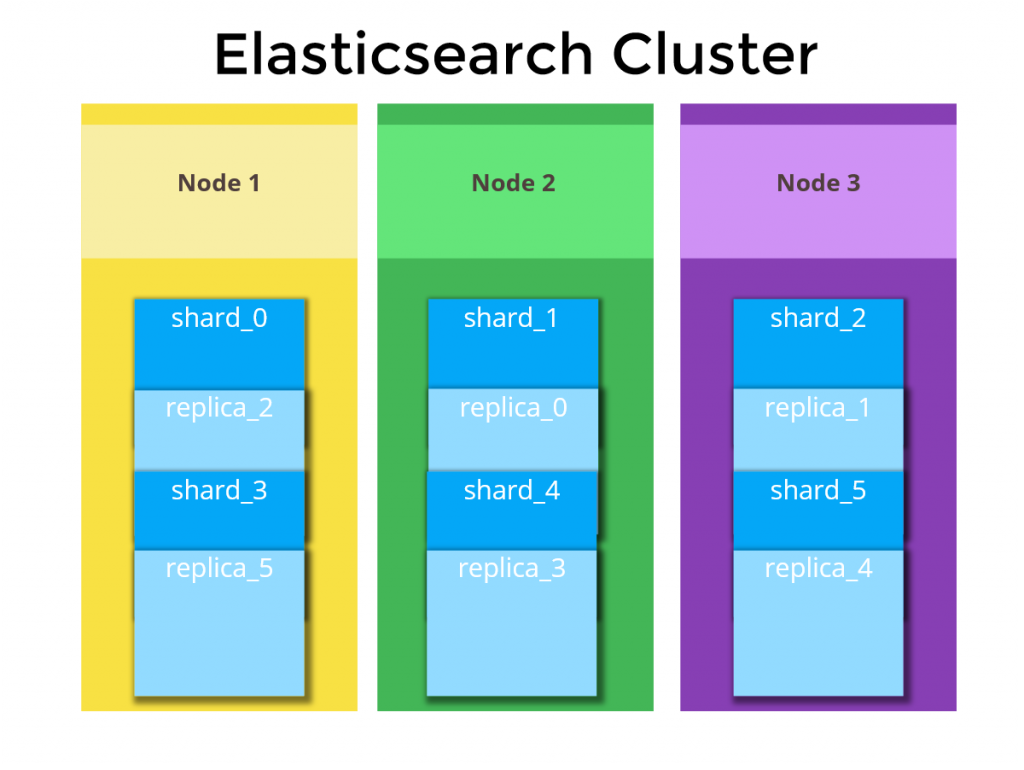 Diagram showing an Elasticsearch cluster with three nodes distributing shards and replicas for data redundancy and scalability
Diagram showing an Elasticsearch cluster with three nodes distributing shards and replicas for data redundancy and scalability
Load Balancing and Query Routing
Coordinator nodes manage incoming queries and route them to appropriate shards using several strategies:
- Round Robin: Distributes queries evenly across available nodes
- Least Connections: Routes to nodes with minimal active connections
- Geographic Routing: Directs queries to geographically closest nodes
- Resource-Based: Considers CPU, memory, and load when routing decisions
Scatter-Gather Operations send queries to multiple shards in parallel, aggregating results before returning responses to users. This parallel processing significantly improves query performance in distributed environments
Performance Optimization
Latency Optimization and Metrics
Modern AI-powered search systems require careful attention to latency metrics that directly impact user experience:
- Time to First Token (TTFT) measures the delay before the system begins streaming results, critical for real-time applications like chatbots where users expect immediate feedback. Target TTFT values vary by application: chatbots need sub-500ms response times, while code completion tools require sub-100ms performance
- Time Per Output Token (TPOT) or Inter-Token Latency measures the rate of subsequent token generation, determining how smoothly results stream to users. Systems should maintain token generation speeds at or above human reading rates for optimal user experience
Total Response Time calculation follows the formula: TTFT + (TPOT × number of generated tokens). This end-to-end metric encompasses the complete user experience from query submission to final result
Multi-Node Deployment Benefits
MoE (Mixture of Experts) architectures like DeepSeek demonstrate how distributed deployments can simultaneously improve both throughput and latency—traditionally conflicting goals. Key insights include:
- Expert Parallelism distributes model experts across multiple GPUs, reducing memory bandwidth pressure per device. Higher expert parallelism (EP) configurations achieve up to 5x throughput improvements while maintaining equivalent latency
- Computation-Communication Overlapping techniques like micro-batching reduce communication overhead by up to 40%. These optimizations hide network latency behind computational work, enabling efficient multi-node operations
Elasticsearch Optimization Strategies
Segment Management significantly impacts search performance through careful tuning of refresh intervals and merge policies:
- Refresh Interval Optimization: Default 1-second refresh provides near-real-time search but can be adjusted based on use case requirements. For bulk indexing operations, disabling refresh (
refresh_interval: -1) dramatically improves throughput - Merge Policy Tuning controls how Lucene segments are consolidated over time. Key parameters include:
segments_per_tier: Controls segment count per tier (default 10, optimize to 5 for better performance)max_merged_segment: Limits maximum segment size (reduce to 1GB for spinning disks)max_thread_count: Adjusts merge thread allocation based on storage type
Force Merge Operations optimize static indices by reducing segment count, improving query performance at the cost of temporary I/O overhead. This technique works best for indices that won’t receive further updates
Production Implementation Considerations
High Availability and Consistency
Eventual Consistency models enable distributed search systems to maintain high availability while managing temporary inconsistencies. Key characteristics include:
- Asynchronous Replication propagates updates across replicas without blocking primary operations. This approach prioritizes availability over strict consistency, suitable for search applications where slight delays are acceptable
- Conflict Resolution Mechanisms handle concurrent updates through strategies like “last writer wins” or application-specific conflict handlers. Vector clocks and timestamps help detect concurrent updates requiring resolution
- Replication Logs maintain sequential records of all write operations, enabling replica synchronization and eventual convergence. Modern implementations use optimized log-structured merge trees for efficient replication
Bulk Operations and Schema Management
Bulk Upload Optimization requires careful management of batch sizes and system resources:
- Reduce bulk sizes during high-load periods to maintain system responsiveness
- Implement separate queues for critical vs. non-critical updates
- Use auto-scaling groups with health flags to handle variable loads
- Cache frequent operations and maintain warm GPU pools for ML workloads
Schema Evolution in dynamic environments requires versioned approaches:
- Track schema changes with incremental version IDs
- Run weekly validation jobs to ensure schema consistency
- Implement graceful degradation when encountering unknown schema versions
Data Tiering Strategies optimize storage costs and performance:
- Hot Tier: Frequently accessed data with 1-second refresh intervals
- Warm Tier: Moderately accessed data with 5-second refresh intervals
- Cold Tier: Archival data with manual refresh on demand
Hybrid Search Implementation
Hybrid Search combines multiple search techniques to leverage the strengths of both lexical and semantic approaches. This strategy typically involves:
- Lexical + Semantic Fusion: Running both BM25-based keyword search and vector similarity search in parallel, then combining results using weighted scoring or reciprocal rank fusion. This approach captures both exact matches and conceptual similarity
- Query Classification: Automatically determining whether queries benefit more from lexical or semantic search, routing them accordingly. Short, specific queries might favor keyword search, while longer, conceptual queries benefit from semantic understanding
- Result Re-ranking: Using machine learning models to re-rank initial results based on user behavior patterns, click-through rates, and contextual signals. This final stage optimizes results for actual user satisfaction rather than just similarity scores
Production Scaling Parameters
Large-Scale Deployment Configuration requires careful parameter tuning based on data volume and query patterns:
- Target shard size: 40GB (approximately 8 million profiles per shard)
- Number of primary shards: Scale to 64 shards for 500 million documents
- Refresh intervals: Hot tier (1s), Warm tier (5s), Cold tier (manual)
- Max concurrent merges per node: 1 merge thread handling 4 segments simultaneously
- Segment merge rate: Approximately 2GB/minute under normal load conditions