A bot that systematically browses the internet for indexing the web pages
This can be used for
- Building Search Engines like Google, Yahoo, Brave, …
- Catch Copy right violations
- Create Web archives like web.archive.org
- Collect data to train ML models
- Academic or Market Research
There are different kinds of web crawlers
- Focused Web Crawler - For research purposes, like history of a stock over past 10 years
- Incremental Crawler - Crawler which gets the updated data of a website which already have been crawled in the past
- Parallel Crawler - We run parallel Threads to crawl the web
- Distributed Crawler - (Focused Web Crawler / Incremental Crawler) + Parallel Crawler + Distributed
Building Search Engine Crawler
Need to build a web crawler which crawls only particular priority pages, or the pages which given to the crawler via seed. We also need to preserve the crawled pages, with duplicate detection and also need to maintain freshness of the crawled pages like updating them
When the bot is crawling a webpage it takes the robots.txt into consideration, in which we define the delay between each request(As bot shouldn’t DDOS the system), allowed paths, dis-allowed paths and so on
# This file tells search engine crawlers (Googlebot, Bingbot, etc.)
# which parts of your site they are allowed or disallowed to crawl.
# It does NOT prevent pages from appearing in search results if other sites link to them.
# For true blocking, use authentication or the "noindex" meta tag.
# =========================
# 1. Global Rule (for all bots)
# =========================
User-agent: * # Applies to all crawlers
Disallow: /admin/ # Don't crawl admin area
Disallow: /private/ # Don't crawl private area
Allow: /public/ # Allow everything inside /public/
Allow: / # Allow root
# =========================
# 2. Specific Bot Rules
# =========================
# Block only Googlebot from a section
User-agent: Googlebot
Disallow: /test-area/ # Don't let Googlebot crawl test area
# Block only Bingbot from certain files
User-agent: Bingbot
Disallow: /temp.html # Block specific file
# =========================
# 3. Sitemap Location (Important for SEO)
# =========================
# Sitemaps help bots discover all URLs efficiently
Sitemap: https://example.com/sitemap.xml
# =========================
# 4. Crawl Delay (not supported by Google, but respected by Bing, Yandex, etc.)
# =========================
User-agent: Bingbot
Crawl-delay: 10 # Wait 10 seconds between requests
# =========================
# 5. Wildcards and Pattern Matching
# =========================
User-agent: *
# Block any URL ending with .pdf
Disallow: /*.pdf$
# Block any URL containing "debug"
Disallow: /*debug*
# Allow PDFs inside /public/reports/
Allow: /public/reports/*.pdfLet’s First Design, Crawler for one URL
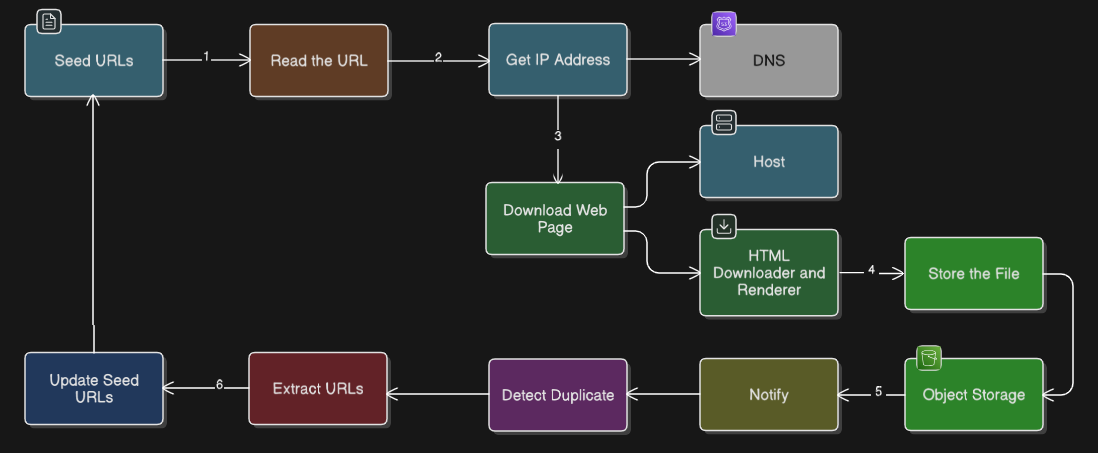
- Get the URL and go to DNS to get the IP
- Store the IP in a cache, such that we don’t need to go under DNS lookup again and again
- Download the website and Parse the HTML content into a object storage
- Detect Duplicate paths of the website, there are three ways
- Use MD5, SHA and other hashing techniques - might cause hash collisions at scale
- Perform Probabilistic matching algorithms like Minhas, fuzzy search, SIM hash(Most of the web crawlers use SIM hash)
Algorithm to crawl the website will be BFS(Breath First Search) as most of the routes will be near to the home not go in depth
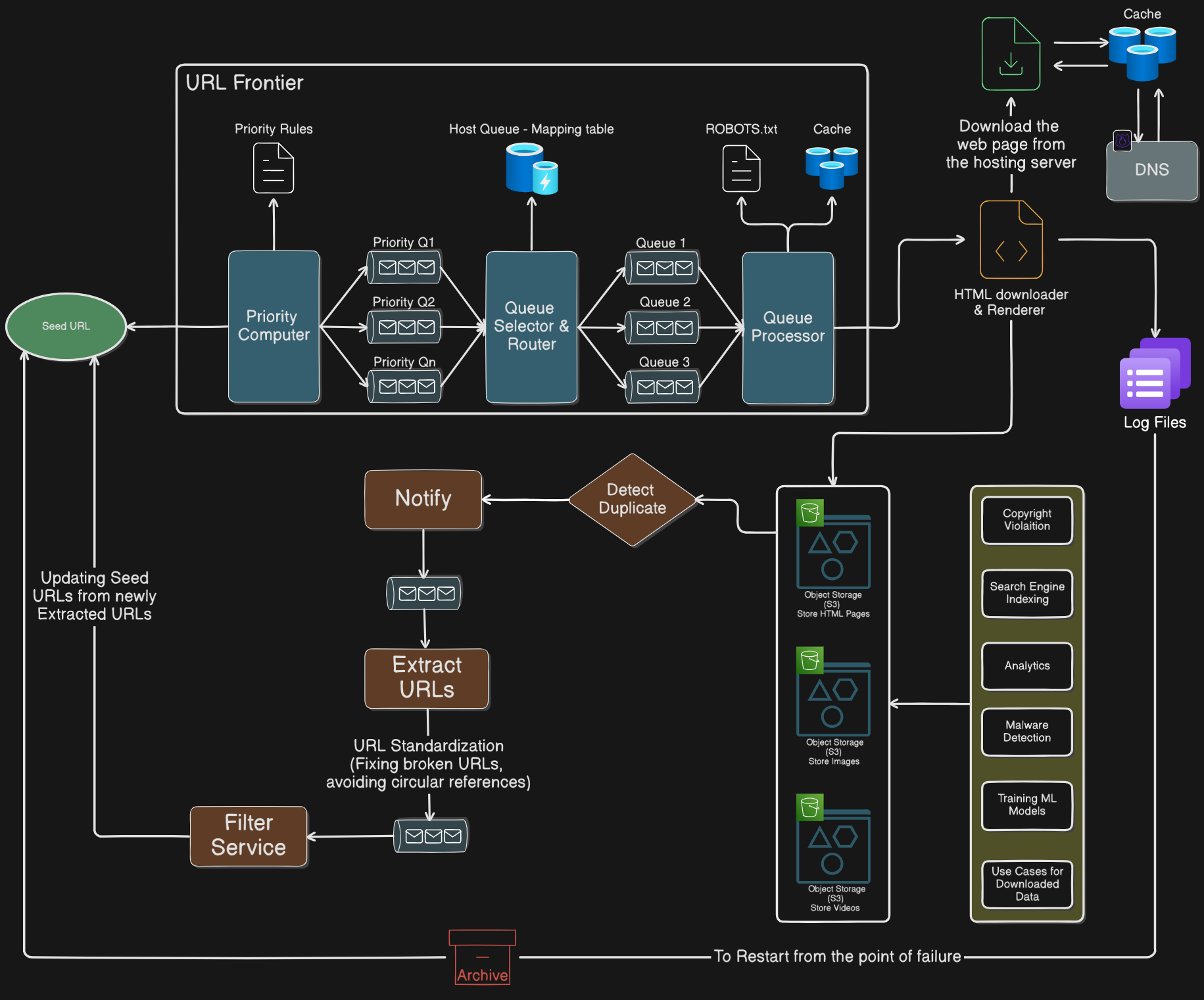
Now Designing the Same System at Scale for multiple websites
- To handle Priority, Politeness and Freshness of the pages we use a data structure called
URL Frontier - In URL Frontier we also have a Q Selector & Router which calculates the priority of the webpage with respect to respected algorithm and store it into a Mapping table
- Store different types of data in different object storages and do the content validation on the object storage like copyright violation
- In the Extract URLs part, we also need to fix the URLs like fixing broken links and avoiding circular references
- Apply Queueing where ever it is possible
- Maintain log files, such that we can continue scraping from the point where system failed